



When Prompts Are Not Enough: A Field Guide to Reliability
If you are building an agent that has to remember what the user decided, here is the finding up front.
The model keeps no state of its own between calls; each turn it sees only what the code sends back in. Left to decide what to record, it skips the writes nothing forces it to make and falls back on the story it has told most often. So the work is to decide, in code, what must be saved, what cannot be overwritten, and what the ending is not allowed to contradict. That surrounding code is the operational context, and reliability is the difference between asking it to behave and making it.
To make this concrete I built a small game master: a thirty-five-turn campaign with one real choice on turn three, an ending that has to honour it at turn thirty, and a bench that crash-tests whether the choice survives. I ran it on Claude Sonnet 4.6, with a cheaper Claude Haiku 4.5 helper in the multi-agent build, in three forms.
The test bed
| Naive | Structured | Multi-agent | |
|---|---|---|---|
| World data | Pasted into the system prompt every turn | Fetched through tools on demand | Fetched by a scoped sub-agent |
| Tools | None | Seven (read and write) | Seven, behind a shared tool server (MCP) |
| Survives restart with decision state? | No | Yes, when it writes | Yes, and guarded |
| Honours a killed branch? | No | No (2 of 3 runs) | Yes |
The naive and structured builds decided for themselves whether to save on any turn; nothing forced them, and that freedom is where they leak. Each rule below is one a build taught me by breaking.
Reproducibility. Every figure comes from the token counts the API returns on each call; the prompts, seeds, and full transcripts are available on request.
Know your memory stack
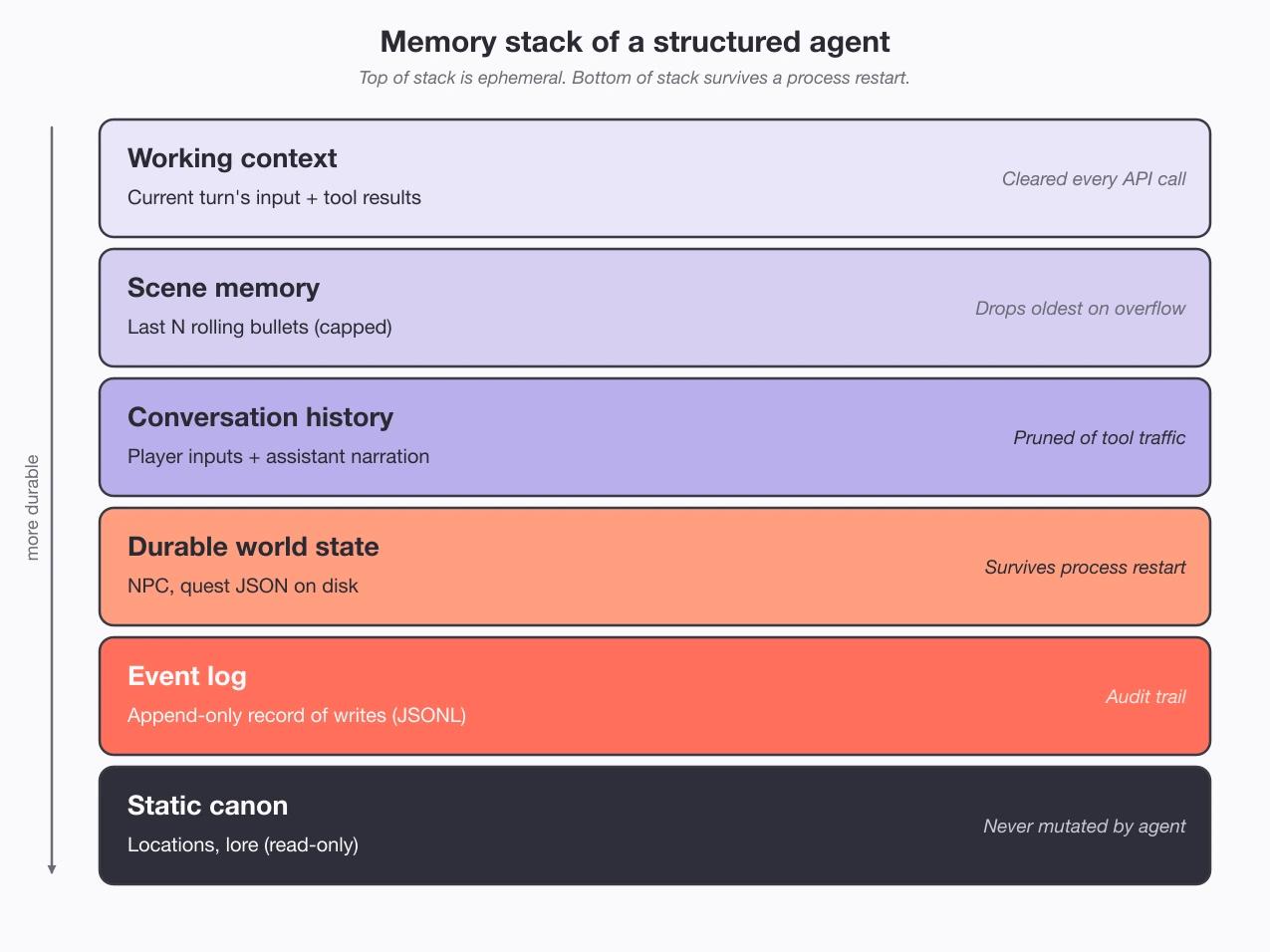
Think of memory as a stack. The top three layers are short-term and vanish when the program closes: the current turn, a few recent-event bullets, and the chat history. The bottom three last: world state in files on disk, an append-only log (a running list the code only ever adds to), and read-only lore. The naive build has none of the bottom three, so closing the laptop takes everything with it. The rule is simple: anything that shapes a later scene has to live in a durable layer.
Force the write
This is the finding that should change how you build. An agent can have a tool for saving, a system prompt (its standing orders every turn) that demands it save, and a player input naming a violent act, and still leave the record untouched.
The branch test proves it: if the player kills the goblin on turn three, the ending should differ from sparing him. On the spared branch the agent dutifully saved its record. On the killed branch, three times running, it never called the save tool.
Sparing produces a character with a future; killing produces a body and apparently nothing worth writing down.
The branch test, all three builds
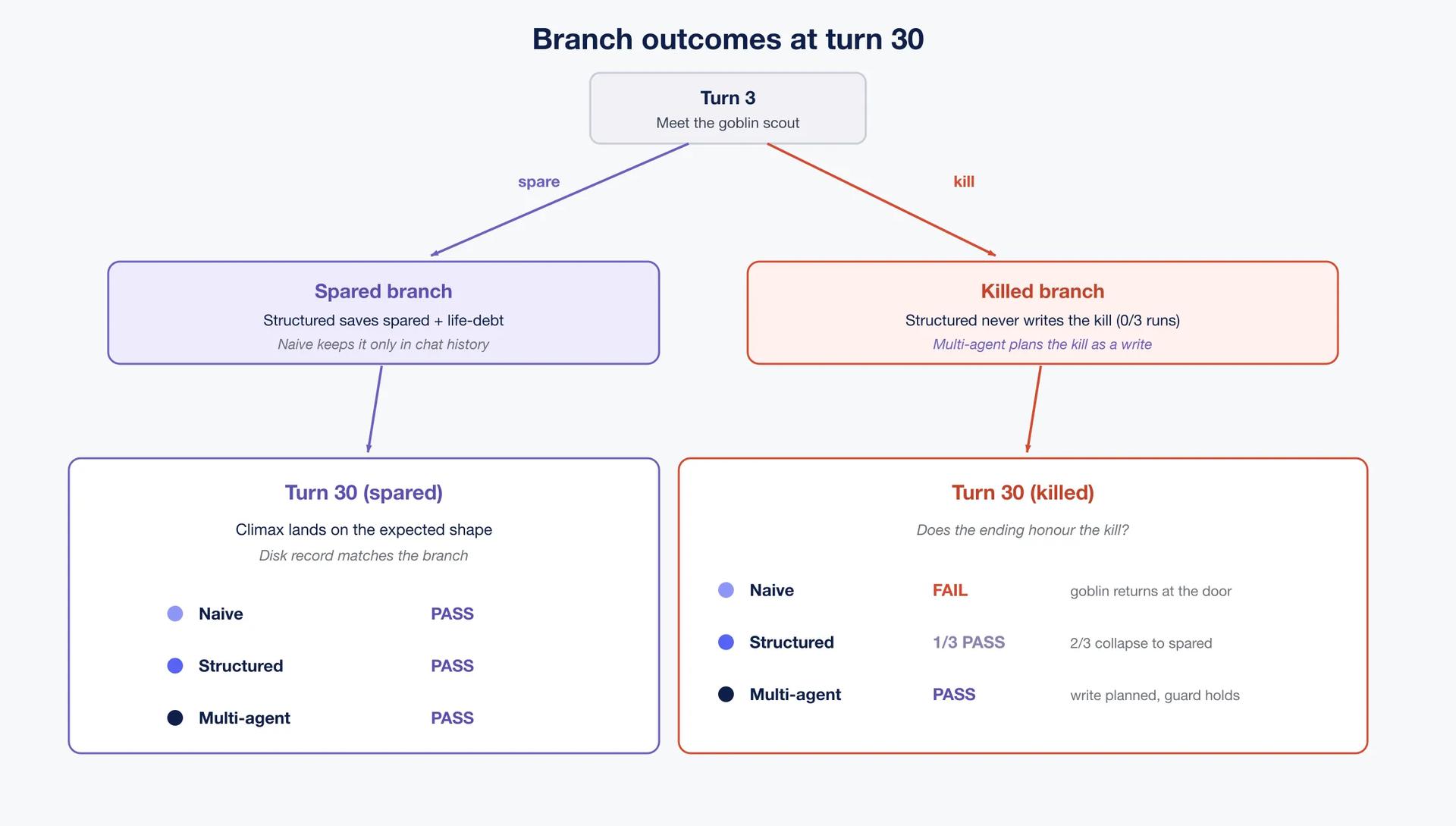
A model's sense of what is worth saving is least reliable on exactly the hard cases, the ones where a human would most want the record kept. So don't leave the save to the model. Force the write from a structured answer the model returns. In the multi-agent build a coordinator plans every turn and a separate worker applies the change because it was planned. The kill goes to disk, and the structured build never managed that across three runs.
Require the read
Forcing the write is half the job. The other half is reading, and it fails two ways. Tools sit unused unless a rule requires a fetch before narrating. Worse, an agent that does fetch can still ignore what it finds: in one run it read the record (goblin alive), then sided with the chat history, which held the kill, and narrated from that. Wipe the chat and the only truth left says he lives.
So require the read, then check the finished prose against the saved record and redo the turn if they disagree. A keyword check will never catch an agent contradicting a record it just wrote.
Set source priority

I planted five contradictions and ran each cold, with no prior conversation to lean on. In four of five the agent collapsed to the same default ending no matter what the contradiction said; when two saved fields disagreed, one always won by accident.
No explicit priority policy existed, so the priority that emerged was accidental, default-biased, and not something I would rely on.
Write the priority down where the model will read it, and better still enforce it in the code that assembles the facts. When two sources genuinely disagree and neither is clearly stale, surface the conflict instead of letting the model quietly pick a winner.
Keep an append-only log
When something surprising happens at turn thirty, you want to trace it back to turn three. An append-only log, entries only added and never edited, is cheap and makes that possible. The skipped write under "force the write" stayed invisible because the log recorded only writes that happened; record the coordinator's intended writes too, and a turn that planned one but never made it stands out at once.
Test what correctness hides
With full chat history intact, every build passes, and a simple keyword check calls them all green. That tells you the rig works, not where the memory came from. The tests that matter take something away:
- Restart safety. Wipe the chat and reopen before the ending. The structured build reloaded the turn-three record and narrated from it, a property of the system; the naive build reached the same ending only because its prompt happened to describe the answer, luck that breaks the moment you ask a different question. In production this is just crash recovery.
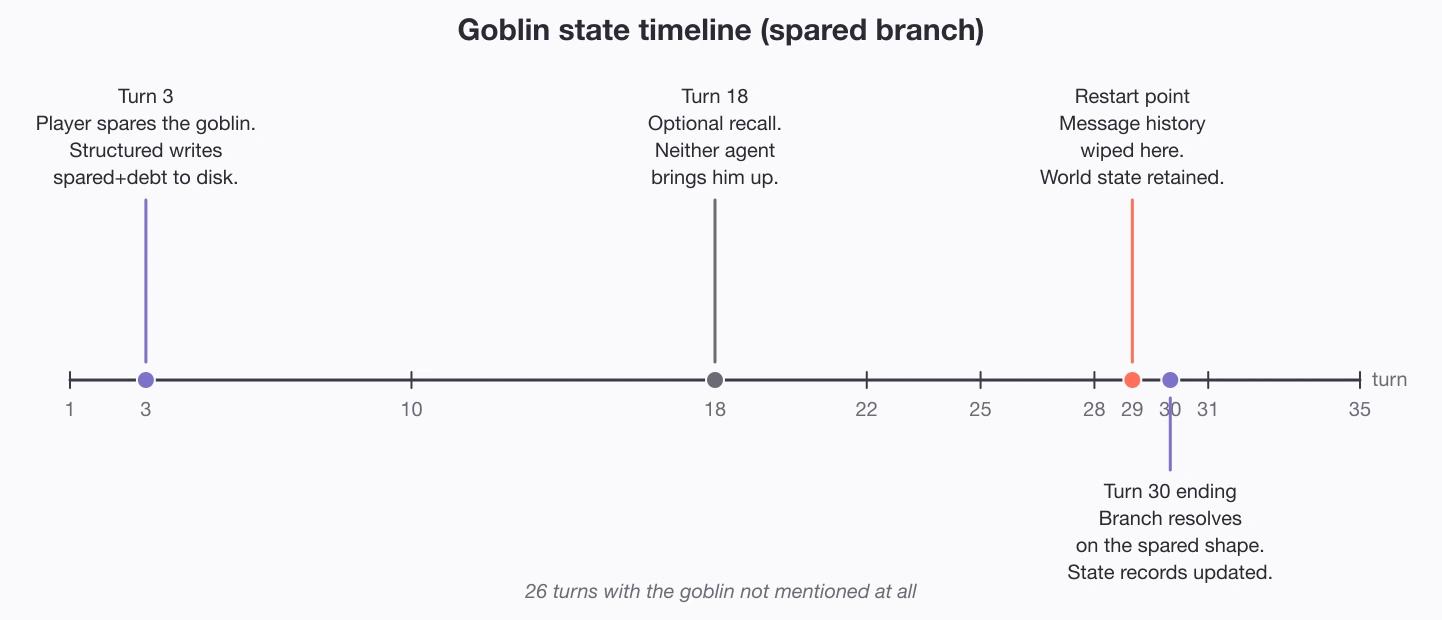
- Branch fidelity. Does the killed ending actually differ from the spared one? Both unsupervised builds fail it: the structured one passes once, by reading chat history, and that pass dies on restart.
- Source priority. Seed disagreements and watch which source wins.
Run them as a ladder, cheap to strict, not a single keyword match.

The cheap keyword check passes runs that are right for the wrong reason; the tool check caught the branch failure, where the prose looked fine but no tool was called. Each rung above reads the saved files, compares prose against disk, and finally checks that the system survives a restart. The keyword check alone would have claimed the data was saved without ever looking.
The architecture
All three enforcement rules point the same way: take the decision off the model and give it to code. The multi-agent build is hub-and-spoke, one coordinator routing small single-purpose workers.
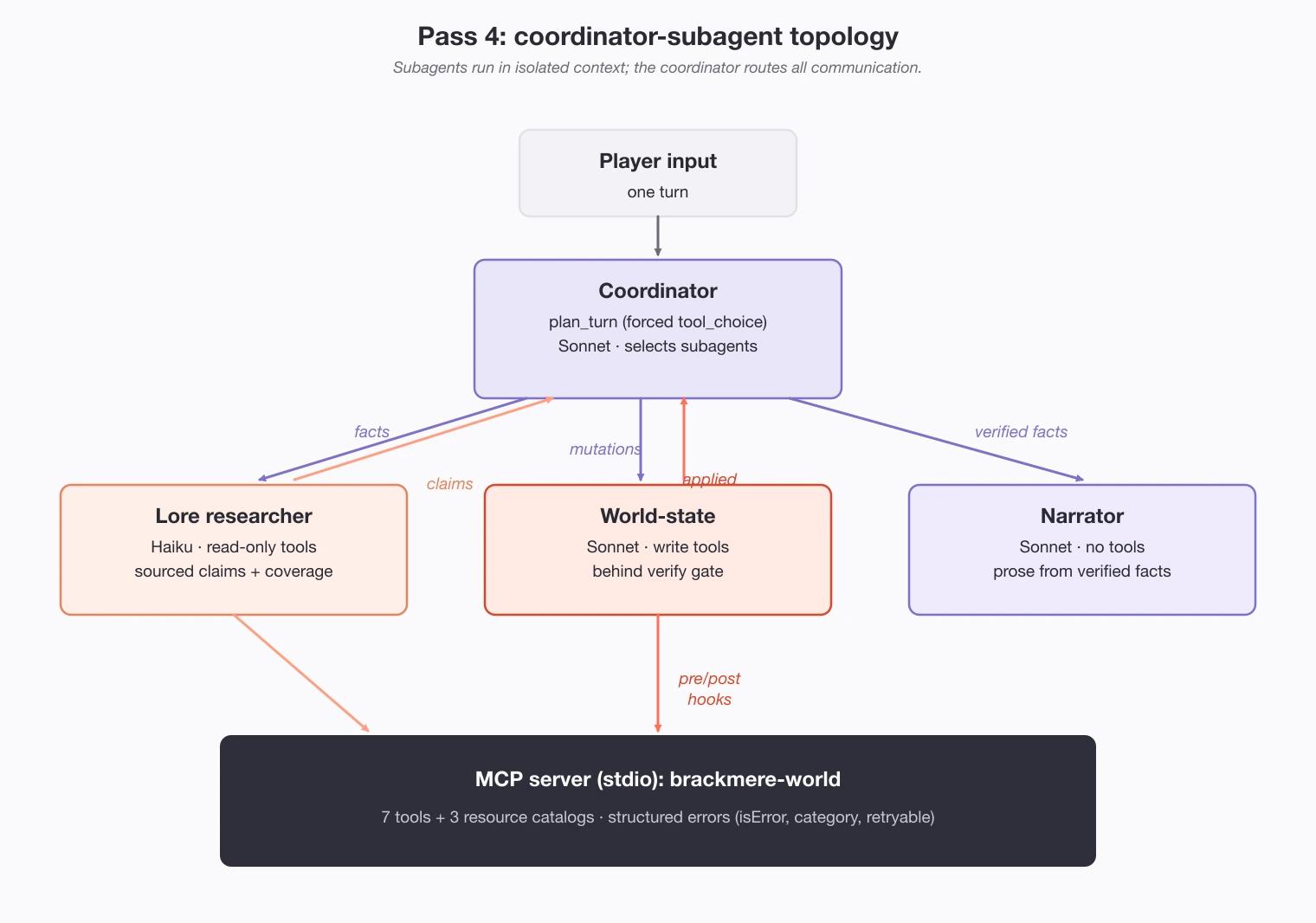
Each turn the coordinator reads the input and must answer in a fixed form rather than free text, listing which facts to look up and which state to change, then routes the work:
- a lore-researcher (Claude Haiku 4.5, read-only) fetches facts and reports them with their source;
- a world-state worker (Claude Sonnet 4.6, write tools) applies the planned changes;
- a narrator (Claude Sonnet 4.6, no tools) writes prose from verified facts, and nothing else.
Each worker sees only the tools it needs, so none can drift into work that is not theirs, and the narrator never sees the raw tool traffic that would let it half-remember a detail and invent the rest. Two guards then hold the record to the end: one refuses to overwrite a death with a living state, the other checks the prose against the record and rewrites the turn on a contradiction. With the goblin dead on disk, the killed branch holds the whole way, which neither unsupervised build managed.
What it costs
| Naive | Structured | Multi-agent | |
|---|---|---|---|
| Cost for a 35-turn campaign | $1.44 | $0.54 | $1.07 |
| Per-turn cost | $0.041 | $0.015 | $0.031 |
Enforcement is not free: four model calls a turn, roughly double the structured build's cost, though still cheaper than the naive build's single bloated call.
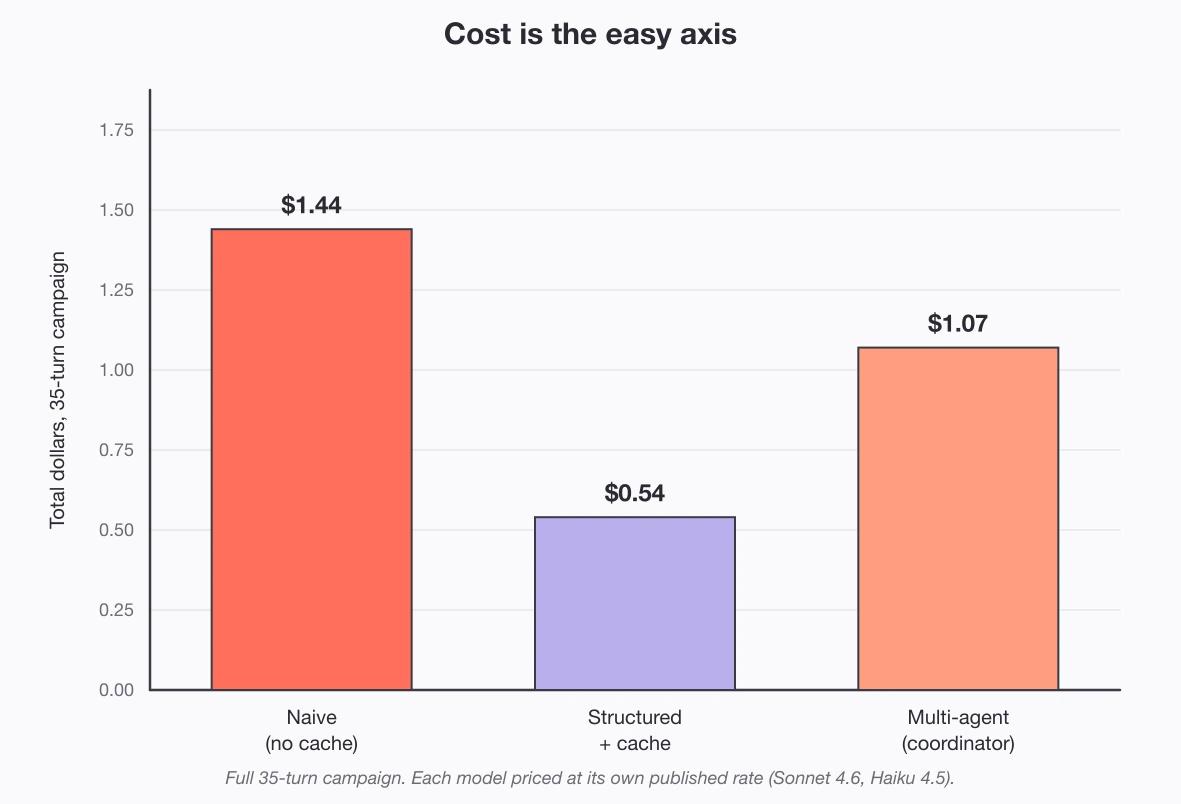

But the whole spread, cheapest run to most expensive, is 90 cents over a full campaign, while reliability is the difference between a system you can ship and one you cannot. Spare the goblin and every build ends right; kill him and only the multi-agent build holds the line.
In closing
The model is a fluent storyteller with no stake in the truth you saved; it writes what it wants and tells the story it has told before. Reliability is something you build into the code around it: decide what must be saved, what cannot be overwritten, and what the ending cannot contradict, then make the code enforce each one. More memory or a firmer prompt will not hold it for you.
Table of Contents
The test bed
Know your memory stack
Force the write
Require the read
Set source priority
Keep an append-only log
Test what correctness hides
The architecture
What it costs
In closing


Continue Exploring
You Might Also Like

A Pattern Language for Transformation
Browse our interactive library of 119 transformation patterns. Each one describes a specific architectural problem and a tested way to solve it, so your team can talk about real tradeoffs instead of abstract ideas.