



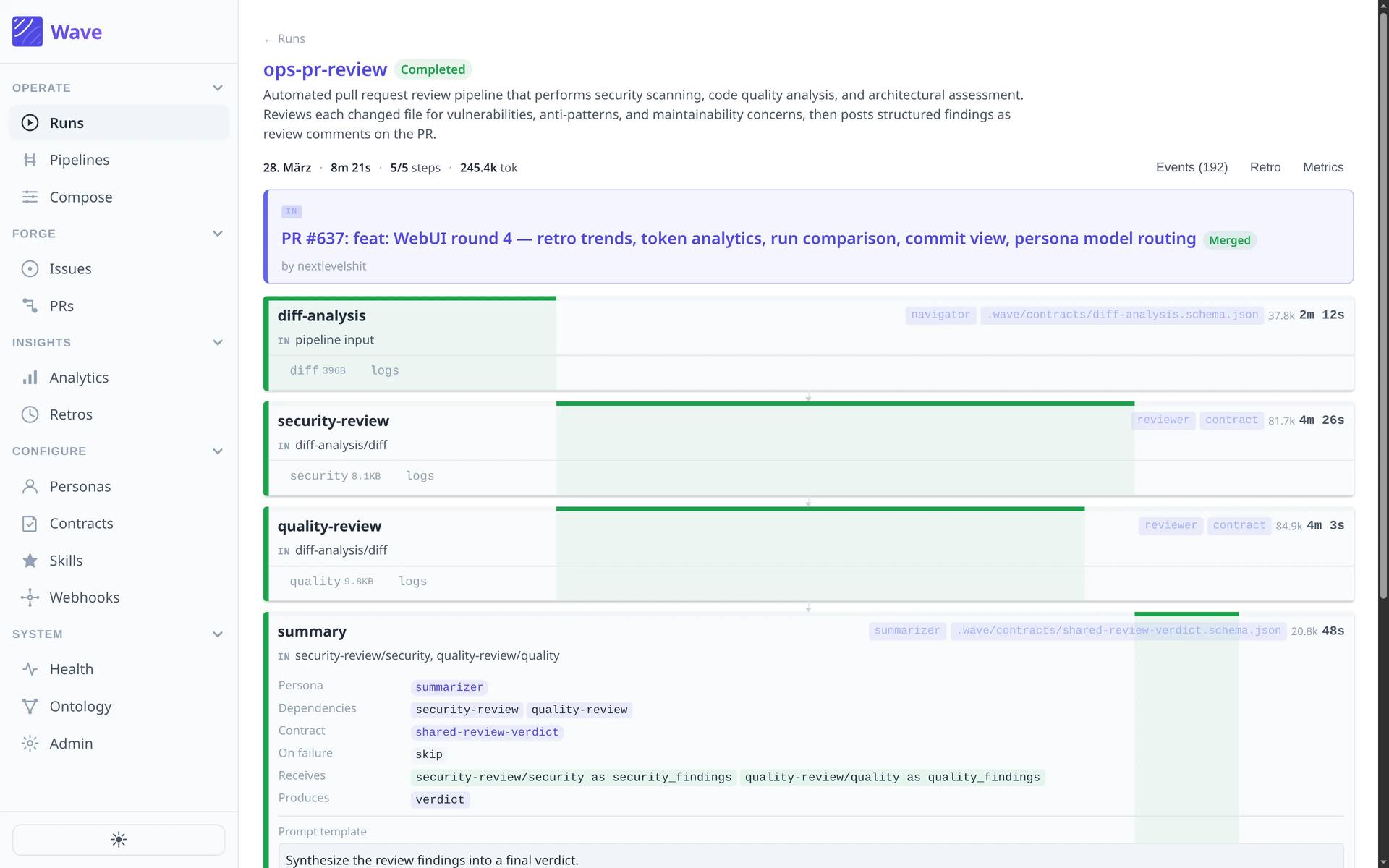
Lore: Shared Context Infrastructure for Claude Code
By Michael Mueller
This is the implementation companion to Building Software Factories. That post described the blueprint. This one describes the platform we built to run it, including what broke along the way.
Every developer on your team is loading context manually. Copy-pasting ADRs into prompts. Explaining the same conventions in every Claude Code session. Watching agents make the same mistakes because they have no memory of what happened yesterday, let alone what the team next door decided last week.
This problem gets worse with scale. Three developers can maintain a shared CLAUDE.md by hand. Fifteen cannot. And once you have multiple repos, multiple teams, and agents running tasks autonomously, the context gap becomes the bottleneck.
We built Lore to close that gap. One install command gives Claude Code access to your org's conventions, architecture decisions, and persistent memory across sessions. It also runs background agents that onboard repos, detect documentation gaps, and review PRs. Everything produces a pull request that humans review and merge.
The problem
Claude Code is powerful when it has context. Without it, you get generic suggestions that ignore your conventions. The agent doesn't know your database schema lives in a Helm chart, not a migration folder. It doesn't know your team decided against Redis last month. It doesn't know another agent already implemented half of what you're asking for.
Most teams work around this with giant CLAUDE.md files, manually maintained, perpetually outdated. Some write shell scripts that dump context into prompts. Others keep shared docs they copy-paste from. None of this scales, and it breaks the moment someone forgets to update the doc after a decision changes.
Why not use what already exists?
The ecosystem is growing. Cursor has project rules. There are RAG-based context injection tools. Most of them solve single-repo context retrieval. Lore searches across every onboarded repo in the org, persists memory that agents share across sessions and teams, and includes a task pipeline that delegates work to agents on Kubernetes. The closest alternative is still a well-maintained CLAUDE.md, which works for one to three developers and breaks beyond that.
What Lore does
Lore is an MCP server that sits between Claude Code and your org's collective knowledge. It auto-detects which repo you're working in from the git remote and serves the right context. No manual loading.
The install takes about 30 seconds:
git clone git@github.com:[GITHUB-ORG]/lore.git && lore/scripts/install.sh
After install, Claude Code has access to MCP tools across three categories: context (org-wide CLAUDE.md, ADRs, hybrid search across all indexed content), memory (persistent store with semantic search, a live knowledge graph, and episode ingestion), and pipeline (delegate tasks to agents running on Kubernetes).
The context tools combine HNSW vector similarity with BM25 keyword matching via Reciprocal Rank Fusion. Early versions used vector-only search, which handled conceptual queries well ("how do we handle auth?") but missed exact matches on function names and config keys. Adding keyword search fixed this without complicating the API.
Memory changed how we work more than the context tools did. When an agent remembers that a particular approach failed yesterday, it stops repeating the mistake. Memories are versioned and searchable by semantic similarity. When running locally, memory operations proxy to the remote server so what one developer learns is available to everyone.
The original memory store was a flat key-value system. That worked for explicit "remember this" commands but missed the knowledge that accumulates passively: what came up in a PR review, what an agent tried and abandoned during a session, which services depend on each other. We added episode ingestion to capture that. write_episode accepts raw text and auto-extracts facts and knowledge graph entities from it. The review-reactor job now captures PR feedback as episodes automatically, and a Claude Code Stop hook captures session summaries at the end of every conversation.
Facts have temporal validity windows. When an agent stores something that contradicts an existing fact, the old one is invalidated via embedding similarity (threshold 0.92). You can query search_memory with include_invalidated to see the history of what the org believed and when it changed.
The extracted entities feed a live knowledge graph in PostgreSQL. query_graph lets agents ask about relationships, like which services talk to the auth library or which teams own what. search_memory can enrich results with 1-hop graph neighbors. assemble_context pulls from all sources and formats the result into a token-budgeted block using configurable YAML templates per task type (review, implementation, research).
None of this works if agents forget to use it. Sessions follow an enforced workflow: assemble_context runs first to load conventions, ADRs, memories, and graph context. search_memory runs before planning or building to check whether the problem was already solved. At session end, write_memory stores a summary and write_episode captures raw session content for passive fact extraction. The enforcement is what makes the knowledge accumulation automatic rather than opt-in.
Four ways to use Lore
Flow 1: Developer with Claude Code
A developer works in their repo. Claude Code connects to the Lore MCP server via stdio and gets org context automatically. They can also delegate tasks to the pipeline without leaving the terminal.

claude "how do we handle auth in this repo?"
# → Pulls from CLAUDE.md, ADRs, team patterns
claude "remember that we decided to use UUIDs for all new tables"
# → Stored via write_memory, searchable next session
claude "create a runbook for database failover in re-cinq/my-service"
# → Task created → agent picks it up → PR appears on the repo
Flow 2: Tasks via Web UI
A product owner or platform engineer creates a task through the dashboard. The Lore Agent processes it by creating a LoreTask custom resource that the controller picks up and executes in an ephemeral Job pod.

Flow 3: PM describes a feature
A PM describes what they want in plain language. Lore fetches repo context, generates a spec, data model, and task breakdown, then opens a PR labeled spec + needs-review. The engineer reviews, merges, and implements with Claude Code using the generated task list.

Flow 4: GitHub Issue dispatch
Add a lore label to any GitHub Issue on an onboarded repo and Lore creates a pipeline task from it. lore:implementation for implementation, lore:review for review. No UI, no CLI, no context switch.

Architecture

Locally, the MCP server runs via stdio but proxies all operations to the backend. Context, memory, and pipeline all require the backend running. The install itself needs no infrastructure, it just configures Claude Code with the MCP server, hooks, and statusline.
On Kubernetes, the MCP server, agent service, LoreTask controller, web UI, and PostgreSQL (with pgvector) handle the full workload. The agent service runs 11 scheduled jobs including gap detection, spec drift checks, review reaction, and eval runs. The full component breakdown and tech stack are in the README.
Every task (runbooks, gap-fill, implementation, review) creates a LoreTask custom resource. This wasn't always the case. We used to split between direct API calls for simple tasks and Job pods for complex ones. We ended up routing everything through the CRD because the execution model was simpler when there was only one path: controller watches the CR, spawns an ephemeral Job pod with a claude-runner container, the container clones the repo, runs Claude Code headless, commits, and pushes. A watcher job polls completed LoreTasks every minute and creates PRs. Every task also creates a GitHub Issue on the target repo with a lore-managed label, so teams see what Lore is doing through tools they already use.
Cost tracking is per-LLM-call with 6-decimal precision: input tokens, output tokens, cost in USD, duration in milliseconds. The analytics dashboard and get_analytics MCP tool expose totals, breakdowns by task type and repo, and 14-day trends. We know exactly what each onboarded repo costs.
What broke along the way
Lore went through many iterations and at the beginning we used more OSS tools, but it taught us what not to build.
The first agent wrapper
The original agent was a wrapper around a third-party coding agent with a black-box output format. Responses came wrapped in unpredictable layers (result fields, code fences, session metadata) and the wrapping changed between calls. We attempted four different fixes to strip the output reliably. All failed. It wasn't a bug in the upstream tool, it was an architectural mismatch: we were parsing unstructured output from a system we didn't control.
The concrete impact: seven or more manual retries per repo onboarding. We eventually removed the wrapper entirely and replaced it with direct Anthropic API calls and Claude Code headless. The removal commit deleted hundreds of lines of parsing workarounds.
Beads
For task tracking, we initially used Dolt, a version-controlled database with CRDT semantics for multi-developer sync. The integration became unstable. Sync didn't work reliably across developers. Task dependency enforcement was missing. We ripped it out and replaced it with PostgreSQL pipeline tasks plus GitHub Issues. The trade-off: we lost CRDT semantics and gained simplicity. After the removal, a gap analysis identified eight critical capabilities that had disappeared, including code parsing (the wrapper had tree-sitter), task dependency enforcement, and silent job failure alerting. We rebuilt selectively, keeping only what we actually needed.
Deploy killing tasks
Every push to main triggered a rollout restart. Implementation tasks that take 30-40 minutes would get killed mid-execution with no recovery. No parallelism. No isolation, so a runaway session could OOM the pod. We lost completed work more than once.
The fix was a Kubernetes CRD called LoreTask, totaling 1,742 lines of code across 17 files. Before: spawn("claude") inside the long-lived agent pod. After: ephemeral Job pods with 1 CPU, 2Gi memory, isolated from the agent lifecycle. If the agent deployment restarts, running Jobs survive.
apiVersion: lore.re-cinq.com/v1alpha1
kind: LoreTask
metadata:
name: impl-abc123
spec:
taskId: "abc123"
taskType: implementation
targetRepo: "your-org/some-service"
branch: "lore/implementation/add-caching"
model: claude-sonnet-4-6
timeoutMinutes: 45
prompt: "Implement caching layer per spec..."
Silent failures
All memory search queries were returning empty results because a database pool reference wasn't being passed through. The function didn't throw. The logs were clean. search_memory just quietly returned nothing, and we didn't notice until someone asked why memory never seemed to work. One missing argument.
Autonomous review and the politics of agent PRs
After an implementation task creates a PR, Lore can trigger a review automatically. The review agent clones the PR branch, reads the spec and repo conventions, and posts comments. On the auto-review path, it gets one iteration to fix issues before escalating to a human. When a human requests changes on an existing agent PR, the review reactor allows up to three fix iterations before adding a needs-human label.
This is opt-in per repo. It had to be. Agents opening PRs across repos owned by different teams is politically charged. Some wanted to try it immediately. Others wanted to see every task before an agent touched their code. The approval gate mechanism exists because of that tension:
{
"required": true,
"label": "approved",
"auto_approve": ["general", "gap-fill"],
"repos": {
"owner/sensitive-repo": { "required": true }
}
}
Teams can require approval even if the global setting is off. The agent checks every 60 seconds for the approved label on the GitHub Issue. General and gap-fill tasks skip the gate by default because their blast radius is small, like a runbook or a documentation patch. Implementation tasks wait.
The mechanism is simple. The conversation that led to it, "we need a way for teams to say no," was the more important design decision.
What we learned
Early versions focused on serving CLAUDE.md and ADRs. That helped, but persistent memory was the bigger change. search_memory with semantic search over extracted facts gets called more than any tool except get_context. Static context tells the agent what the conventions are. Memory tells it what was tried, what failed, and what the team decided last week. The second kind of knowledge is harder to write down and more useful.
The 3rd party wrapper experience taught us that wrapping a black-box system and parsing its output is a losing strategy. Four attempts at output stripping, all failed. When we switched to direct API calls with structured output, the parsing problems went away.
After removing 3rd party wrapper and Beads, we had a list of eight gaps. We didn't rebuild all of them. Some capabilities, like CRDT sync and the original tree-sitter integration, turned out to be unnecessary for the workflows we actually ran. The system got simpler.
The memory search bug taught us that agent infrastructure needs the same observability as any production system. A clean log doesn't mean things are working. We added health checks and the agent_stats tool after that one. More recently we added persistent log storage. Every Job pod's output goes to GCS with a redaction pipeline that strips API keys, JWTs, and connection strings before storage. The web UI reads logs per-task with GitHub-based access control. When something goes wrong now, we can actually look at what happened.
What's next
The knowledge graph, episode ingestion, and temporal facts shipped recently. That was the biggest pending item from a month ago. The nightly context quality evaluator, the weekly autoresearch loop, and spec drift detection are all running.
Still pending: a local read cache so developer installs don't hit the remote API on every read query, and retrieval latency optimization. We're tracking p50/p95/p99 per MCP tool in the analytics dashboard but haven't started tuning yet.
The hard problems we haven't solved: when parallel Jobs touch the same files, merging their output is manual. Sonnet implementation tasks cost real money and we're still figuring out the right task-to-model mapping. And the autoresearch loop exists but tuning the PromptFoo eval suites, deciding what "good context" actually means, is ongoing.
Getting started
The install configures Claude Code locally (MCP server, hooks, statusline) and takes about 30 seconds. No infrastructure needed for setup.
git clone git@github.com:[GITHUB_ORG]/lore.git
cd lore && scripts/install.sh
The MCP server runs locally via stdio but proxies all context, memory, and pipeline operations to the backend via LORE_API_URL. There is no local-only mode anymore. The backend (vector search, agent pipeline, web UI) runs on GKE with all infrastructure Terraform-managed.
If your team runs Claude Code across multiple repos and spends time on context that should be automatic, that is the problem Lore solves.
Resources:
- Lore on GitHub - full architecture, tech stack, MCP tool reference, and deployment guide
- MCP Protocol
- re:cinq
Table of Contents
The problem
What Lore does
Four ways to use Lore
Architecture
What broke along the way
Autonomous review and the politics of agent PRs
What we learned
What's next
Getting started

Continue Exploring
You Might Also Like

A Pattern Language for Transformation
Browse our interactive library of 119 transformation patterns. Each one describes a specific architectural problem and a tested way to solve it, so your team can talk about real tradeoffs instead of abstract ideas.