



Building a Privacy Gateway for German Lawyers
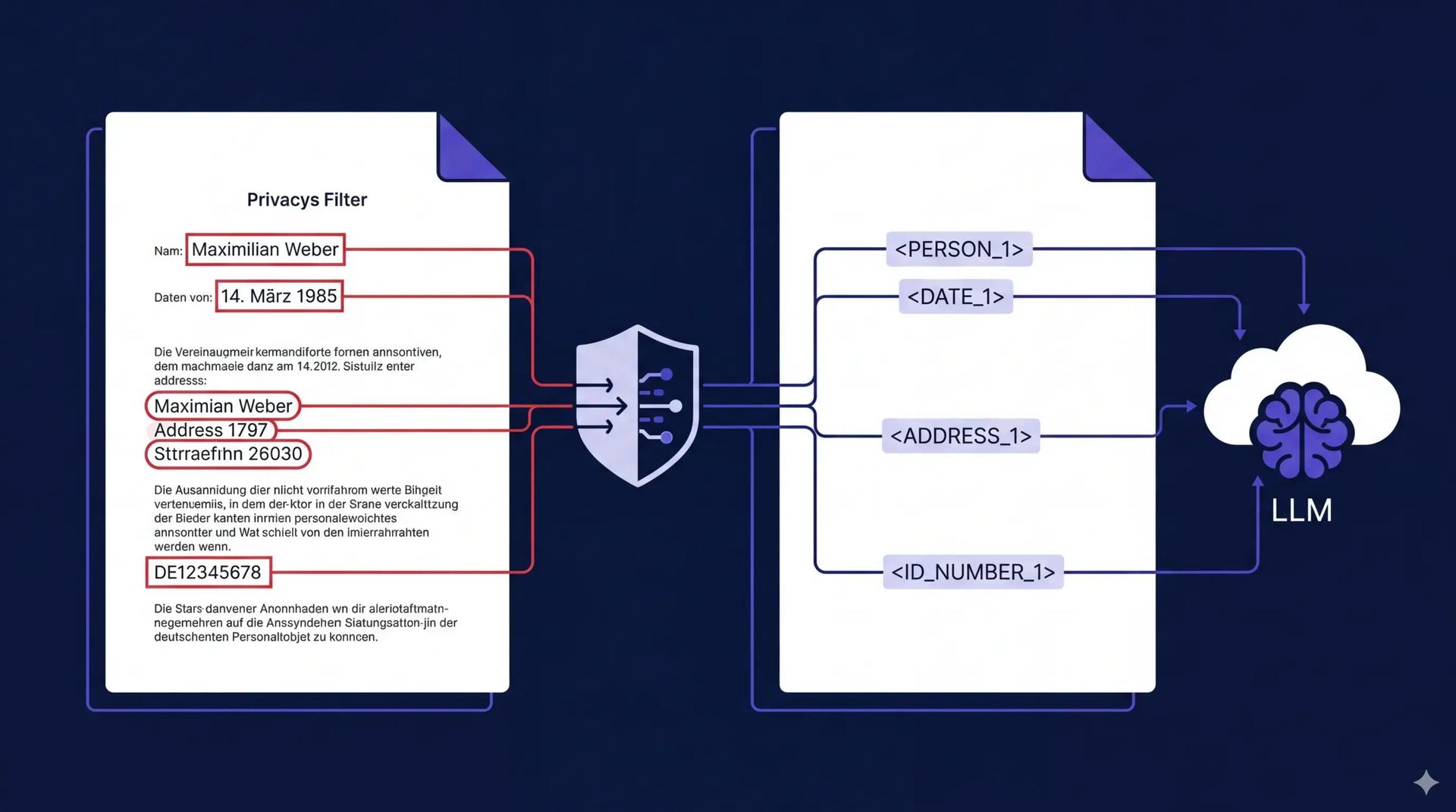
German lawyers are bound by strict professional secrecy rules (BRAO §43a) and GDPR. They can't use cloud LLMs because their work — contracts, court filings, client communications — is full of personal data that can't leave their infrastructure. We built a self-hosted gateway that strips all PII from legal text before it reaches the cloud, then restores it in the response. The lawyer gets the full benefit of a frontier LLM without any client data crossing the network boundary.
This post covers the architecture, the PII detection stack, and how the whole thing runs on a single NVIDIA DGX Spark.
The problem
A lawyer pastes a Schriftsatz (client communication or similar) into a chat UI. The text contains names, birthdates, tax IDs, court case numbers, addresses, bank account details. If that text goes to a cloud API as-is, the lawyer has a compliance problem. Manual redaction is tedious and error-prone. The alternative is not using LLMs at all, which is increasingly impractical.
How it works
The pipeline has two phases. Phase one runs entirely on the local machine and handles anonymization. Phase two sends only the cleaned text to the cloud.
User input (German legal text)
→ Presidio + Flair NER (detect PII)
→ Anonymizer (replace with tokens: <PERSON_1>, <DE_STEUER_ID_1>, ...)
→ LLM Guard prompt injection check
→ User reviews anonymized text, can edit
→ Gemini API (sees only tokens, never real data)
→ De-anonymizer (restore original values in response)
→ User sees the answer with real names back in place
The mapping table (<PERSON_1> → "Thomas Müller") never leaves the server. It's stored in PostgreSQL, encrypted at rest. The cloud LLM only ever sees placeholder tokens.
PII detection: Flair beats spaCy for German legal text
We started with spaCy's de_core_news_lg model for named entity recognition. It missed names with titles ("Dr. Christian Schmidt"), names in formal letter headers, and compound names common in legal correspondence. Switching to Flair's ner-german-large model fixed most of these. Flair consistently scores 1.0 confidence on German person names that spaCy missed entirely.
The tradeoff is speed — Flair runs at about 200ms per sentence versus 50ms for spaCy. On the DGX Spark hardware, that's not noticeable in practice.
On top of Flair, we run 12 regex-based recognizers through Presidio for patterns that NER models don't catch:
- Aktenzeichen — court case file numbers like
3 O 123/24orVII ZR 45/23 - Steuer-ID — 11-digit German tax identification numbers
- Sozialversicherungsnummer — social security numbers
- Handelsregister — commercial register entries (HRB, HRA)
- Personalausweis — ID card numbers
- Geburtsdatum — context-aware birthdate detection (only dates near keywords like "geb." or "Geburtsdatum" — contract dates pass through untouched)
- Rechtsanwalt — lawyer registration numbers
- Kontonummer, BIC, Vertragsnummer, Kundennummer — financial identifiers for bank statements and credit contracts
Each recognizer uses Presidio's context-boosting: a low base score that gets raised when relevant keywords appear nearby. This keeps false positives low. "12345678901" alone won't trigger the Steuer-ID recognizer, but "Steuer-ID: 12345678901" will.
Overlapping entities
One problem we hit early: Presidio's birthdate recognizer and the date-time recognizer both fire on the same text span. "geb. 15.03.1978" triggers DE_BIRTHDATE at score 0.9 and DATE_TIME at score 0.6. If you anonymize both, you get mangled tokens like <DE_BI<DATE_TIME_1>.
The fix is a deduplication pass before anonymization. Sort by start position, then by score descending. If two spans overlap, keep the higher-scored one.
def _deduplicate_overlapping(results):
sorted_results = sorted(results, key=lambda r: (r.start, -r.score))
deduplicated = []
last_end = -1
for result in sorted_results:
if result.start >= last_end:
deduplicated.append(result)
last_end = result.end
return deduplicated
Consistent tokens across conversation turns
The anonymizer maintains a session-scoped mapping table. If "Thomas Müller" appears in message 1 and gets assigned <PERSON_1>, it keeps that same token in message 3. This matters because the LLM needs to see a coherent conversation — if the same person gets a different token each turn, the model can't track who's who.
def get_or_create_token(original, entity_type, mapping):
for token, value in mapping.items():
if value == original and token.startswith(f"<{entity_type}_"):
return token
count = sum(1 for t in mapping if t.startswith(f"<{entity_type}_"))
return f"<{entity_type}_{count + 1}>"
Prompt injection protection
We added LLM Guard's PromptInjection scanner to catch attempts at manipulating the LLM through crafted inputs. It runs a DeBERTa v3 classifier on the anonymized text and flags anything above a 0.92 confidence threshold. In testing, "Ignore all previous instructions" scores 1.0 and gets blocked. Normal legal text scores below 0.1.
The scanner is lazy-loaded — the model downloads on first use and stays in memory. It adds about 200ms to each request.
OCR for scanned documents
German law firms still deal with a lot of paper. Scanned PDFs are common — court filings, notarized documents, older contracts. We run Baidu's Qianfan-OCR (4B parameter vision-language model) through vLLM as a separate k8s pod. When PyPDF2 can't extract text from a PDF page, the page gets rendered as an image at 200 DPI via PyMuPDF and sent to the OCR service through its OpenAI-compatible API.
The OCR pod uses about 8GB of GPU memory at 30% utilization, leaving plenty of room on the DGX Spark's 128GB unified memory.
Legal source lookup
When the anonymized text contains references to German law — paragraph numbers like "§ 1605 BGB", case numbers, or legal keywords — the system searches for the actual legal text and injects it as context for Gemini. Sources:
- gesetze-im-internet.de — we download and parse the XML exports for the 20 most common German laws (BGB, StGB, ZPO, FamFG, etc.) at startup. Paragraph lookups are instant from the in-memory index.
- openlegaldata.io — REST API for court decisions. Searched by Aktenzeichen or keywords.
- dejure.org — citation redirect endpoint for generating clickable links to court decisions. No content scraping (their ToS prohibit it).
The retrieved sources get prepended to the prompt with numbered references, and Gemini is instructed to cite them. The frontend renders a collapsible "Quellen" panel below each response with clickable links to the original sources.
The two-phase UX
We initially built a single-step flow: user sends message, everything runs, response appears. The problem was that Presidio sometimes gets things wrong — it might miss a name or tag a legal term as a person. Sending that to the cloud without human review defeats the purpose.
The current flow splits into two phases:
- User sends text. Presidio runs (~1 second). A review card appears showing the anonymized text with a mapping table. The user can remove false positives (click X on an entity pill) or select missed text and add it manually through a floating popover.
- User clicks "An LLM senden" with an optional prompt ("Fasse die Haftungsklauseln zusammen"). The anonymized text plus prompt go to Gemini. Response comes back de-anonymized.
This gives the lawyer full control over what leaves the machine.
Running on the DGX Spark
The whole stack runs on a single NVIDIA DGX Spark (GB10 Grace Blackwell, 128GB unified memory, arm64) under k3s. Four pods:
| Pod | What it does | Resources |
|---|---|---|
| backend | FastAPI, Presidio, Flair NER, LLM Guard | CPU + ~2GB for Flair model |
| frontend | React SPA served by nginx | Minimal |
| ocr | Qianfan-OCR 4B via vLLM | GPU, ~8GB VRAM |
| privacy-db | PostgreSQL via CloudNativePG | 10GB storage |
The backend image is built for linux/arm64 since the DGX Spark runs an Arm CPU. We hit this early — x86 images fail silently on k3s without useful error messages.
All k8s manifests use Kustomize with overlays for dev (CPU fallback, no GPU) and prod (GPU runtime class, DGX-specific settings).
What we'd do differently
The Flair false positive list is manual. We maintain a blocklist of German legal terms that Flair wrongly tags as PERSON — words like "Familienrechtliche" and "Barunterhalts". A better approach would be fine-tuning the NER model on a German legal corpus, but that requires annotated training data we don't have yet.
The vLLM OCR pod takes about 2 minutes to start cold (model download + CUDA graph capture). A readiness probe and some patience on first deploy would save debugging time.
We also considered using LLM Guard's Anonymize scanner to replace Presidio entirely. After digging into the API, we found it doesn't support registering custom EntityRecognizer subclasses — only regex patterns and a fixed NER model slot. So we kept Presidio for PII detection and use LLM Guard only for prompt injection.
Stack
- Backend: Python 3.11, FastAPI, Presidio, Flair
ner-german-large, LLM Guard - Frontend: Vite, React 19, TypeScript, Tailwind CSS 4
- Cloud LLM: Gemini 2.5 Flash via Vertex AI
- OCR: Qianfan-OCR 4B via vLLM
- Database: PostgreSQL via CloudNativePG
- Infrastructure: k3s, Kustomize, NVIDIA DGX Spark (arm64)
Resources
Table of Contents
The problem
How it works
PII detection: Flair beats spaCy for German legal text
Overlapping entities
Consistent tokens across conversation turns
Prompt injection protection
OCR for scanned documents
Legal source lookup
The two-phase UX
Running on the DGX Spark
What we'd do differently
Stack
Resources

Continue Exploring
You Might Also Like

A Pattern Language for Transformation
Browse our interactive library of 119 transformation patterns. Each one describes a specific architectural problem and a tested way to solve it, so your team can talk about real tradeoffs instead of abstract ideas.