



Measuring AI Agent Quality When You Can't Freeze the Data
By Michael Czechowski
My previous employer was a publisher. We built translation models, and whenever we shipped a new version, the check was simple: same input, two models, outputs side by side. You looked at both and formed a judgment.
When we needed the same kind of check on the CFO agent, I started there.
Side by Side
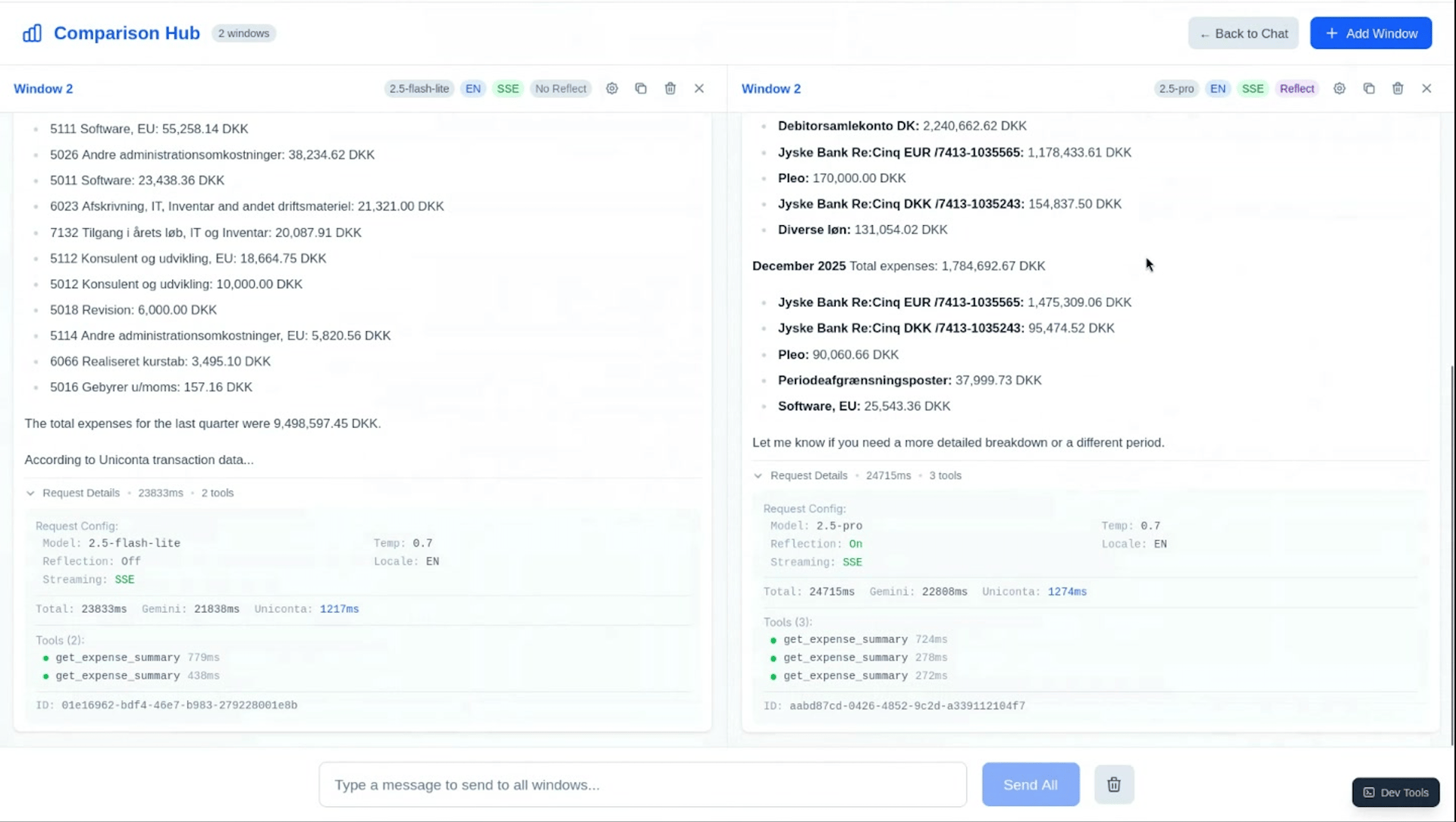
The CFO agent connects to Unicontas accounts and answers questions about financial data in natural language. My colleague Gabi was focused on model evaluation; I built the observability and developer tooling. We needed a way to compare model configurations without writing new financial queries from scratch — I'm not a finance person, and working through accounting problems I don't understand from scratch takes longer than it should.
I built a multi-window comparison interface into our custom developer tools. You pick two configurations — model, temperature, system prompt variant — load a query from a pre-built library, and send to both. Outputs appear side by side.
A few things I found building it:
The Unicontas API doesn't support parallel requests, so both calls run sequentially. The responses are a few seconds apart — close enough for most queries, but not strictly simultaneous.
Having a library of pre-loaded queries mattered more than I expected. Without it, each session started with me trying to construct financial questions I didn't have the domain knowledge to validate.
What the comparison shows quickly is formatting quality. Gemini 2.5 Pro consistently returns better-structured responses than Flash — clearer markdown, more appropriate number presentation, better hierarchy. Whether the numbers themselves are correct is a separate question.
The Question Nobody Had an Answer To
In the knowledge-sharing session where Gabi and I walked the team through what we'd built, someone asked: "Have you got to the point of trying to objectively measure those?"
We hadn't. According to LangChain's State of Agent Engineering report (n=1,340, late 2025), 89% of organisations working with agents have implemented observability, but only 52% run formal evaluations. Most teams get visibility before they get measurement. That was roughly where we were.
The reason objective measurement is harder than it sounds comes down to the data the agent works with.
Uniconta is a live accounting system. There's no test instance. The right answer to "what was Q3 revenue?" changes depending on when you ask it — whether entries have been reconciled, whether the period is closed. To build a static evaluation set, you'd need a test company with controlled transaction history — frozen balances, known data. Setting that up takes time, and temporal queries would have different correct answers next month regardless.
What we could measure was certainty. Our agent uses a reflection pattern: after generating a response, it checks whether the answer meets a confidence threshold and retries if not. That tells you the model flagged its own uncertainty. Whether what it said was accurate is a different measurement.
What LLM-as-a-Judge Evaluation Requires
The approach that makes sense next is LLM-as-a-judge: run queries against a defined expectation of what a good response looks like, then use a separate model to evaluate whether the actual response meets that definition. In the LangChain survey, 53% of organisations already use this approach alongside human review.
Tools like RAGAS, DeepEval and Braintrust have made the infrastructure easier to set up. But the tooling is secondary. The prerequisite is a definition of "good" that exists before the evaluation runs — and for agents querying live data, that definition needs ground truth to compare against.
For the CFO agent, the clearest starting point is queries with deterministic answers. If a company had €450,000 in Q3 revenue and you ask for Q3 revenue, the answer should be €450,000. Build the evaluation set from questions like those. Gradually expand to more qualitative dimensions — formatting, reasoning, appropriate level of detail — once the factual baseline is solid.
One thing to know going in: LLM judges have documented biases. They tend to favour longer, better-formatted responses regardless of accuracy, and outputs that resemble their own style. Running your judge against 50–100 human-labelled examples before trusting it tells you whether it's measuring what you think it is.
Why We Skipped LangChain
One thing that came up in the same session: we built the CFO agent directly against the Vertex AI SDK, without an abstraction layer like LangChain.
A colleague framed the reasoning clearly: if you eventually want a framework that abstracts across providers, coding to the SDK first means you understand what the framework is doing for you. You can weigh that tradeoff from a position of knowledge rather than inheriting the complexity without knowing what it costs.
For us, that was the right call. The agent's tool definitions, prompt management, and model calls are all straightforward to read and modify. Engineers who haven't touched the codebase before can follow what it does.
This has broader support in the field — engineers who've measured it report 15–30% latency overhead with LangChain compared to direct API calls, and the "rewrite from LangChain" story is common enough on Hacker News to be a genre. That's not a case against using it; it's a reason to understand what you're getting before you reach for it.
If I Were Starting Over
Build the comparison tool before the agent, not alongside it. Having a way to see two model responses next to each other is immediately useful — as much for building intuition about what different configurations do as for any formal evaluation.
And think about the ground truth problem from the beginning. We got to the "how do you objectively measure this" question after several weeks of qualitative comparison. Starting with a handful of deterministic test cases from day one would have given us something concrete to test against as the agent developed.
More from the team at re-cinq.com/blog.
Table of Contents
Side by Side
The Question Nobody Had an Answer To
What LLM-as-a-Judge Evaluation Requires
Why We Skipped LangChain
If I Were Starting Over



Continue Exploring
You Might Also Like

A Pattern Language for Transformation
Browse our interactive library of 119 transformation patterns. Each one describes a specific architectural problem and a tested way to solve it, so your team can talk about real tradeoffs instead of abstract ideas.