



Building an Automated AI News Digest with n8n and Google Vertex AI
By Michael Mueller
In our last post, we did a deep dive into connecting Slack and Atlassian with an AI chatbot. This time, we're tackling another universal business challenge: information overload. Specifically, we'll build a system to automatically tame the firehose of AI news, using n8n to create a sophisticated, AI-powered news analysis and curation pipeline.
Unlike our previous Kubernetes-heavy deployment, the beauty of this workflow lies in its elegant orchestration within n8n itself. It's a perfect example of how to build a powerful data processing pipeline without complex infrastructure. The workflow moves data through a clear, logical sequence: Ingestion → Aggregation → AI Analysis → Data Wrangling → Curation & Delivery.
Let's Talk About a Problem We All Know - Taming the AI News Firehose
If you're in the tech industry, you know the feeling. Every morning, there's a tidal wave of articles, blog posts, and announcements about [INSERT RANDOM TECH IN HERE]. It's a full-time job just to keep up, let alone separate the meaningful trends from the fleeting hype. How do you ensure you and your team is informed about the developments that actually matters to your business?
Manually sifting through dozens of sources and then sharing on Slack is inefficient and inconsistent. What you really want is an automated analyst—a system that can read everything, understand it, score its relevance, and deliver a concise summary of the most important news directly to you and your team.
This isn't just about saving time; it's about making sure critical developments don't slip through the cracks. When a new AI framework emerges that could transform your development workflow, or when funding patterns signal a shift in market priorities, your team needs to know about it quickly and accurately. The alternative is making strategic decisions with incomplete information, or worse, learning about game-changing trends weeks after your competitors.
This is exactly what we're going to build. We'll use the developer-first automation of n8n to create a workflow that fetches articles from top tech news sources, uses Google's powerful Gemini models via Vertex AI to perform a deep analysis of each one, and then delivers a curated "Top Trends" digest to a Slack channel and logs it in Google Sheets for archiving.
The Engine Room: n8n for Intelligent Data Processing
Similar to our previous Atlassian chatbot project, we're using n8n as our automation engine. But this time, instead of orchestrating conversational AI, we're building a pipeline that can ingest, analyze, and curate information at scale.
n8n's Native AI Capabilities: Building the Analysis Engine
The choice of n8n allows us to leverage its native support for AI workflows without complex infrastructure. The platform provides dedicated nodes for creating AI agents that can process large batches of data, apply intelligent filtering, and generate structured outputs. We can define the agent's analytical goals, choose our LLM, and create a seamless pipeline from raw data ingestion to intelligent curation.
Architectural Overview: From Raw Feeds to Intelligent Digest
Here's a look at the key components of our n8n workflow and the role each one plays:
| Component | Role in the Architecture |
|---|---|
| Schedule Trigger | The pacemaker of our workflow. It kicks off the entire process at a set time every day, ensuring a fresh digest is ready for the team each morning. |
| RSS & HTTP Nodes | Our data collectors. These nodes reach out to various news sources (like TechCrunch, MIT Technology Review, Wired, and O'Reilly) via their RSS feeds and to services like NewsAPI.org to gather the raw articles. |
| Merge Node | The funnel. It takes all the articles gathered from the different sources and combines them into a single, unified stream of data for processing. |
| AI Agent & Vertex AI | The brain of the operation. We use n8n's native AI Agent, powered by a Google Vertex AI (Gemini) model, to read each article and return a structured JSON object containing a summary, keywords, sentiment, and a relevance score. |
| Code & Merge Nodes | The data wranglers. These nodes perform critical data manipulation—adding unique IDs to track articles through the AI process, parsing the AI's JSON output, and then re-combining the original article data with its new AI-generated analysis. |
| Filter (If Node) | The curator. This node acts as a gatekeeper, only allowing articles with a high relevance score (as determined by our AI) to pass through to the final digest. |
| Slack & Google Sheets Nodes | The delivery network. The final, curated articles are formatted into a clean Markdown digest and posted to a designated Slack channel, while also being appended to a Google Sheet for a permanent, searchable archive. |
This entire pipeline is built visually on the n8n canvas, giving us a clear, maintainable, and easily adaptable system for automated intelligence gathering.
Crafting the AI Curation Workflow in n8n
With the architecture mapped out, let's walk through the n8n canvas. This is where we wire together the nodes that bring our AI news analyst to life. Before you begin, ensure you have credentials configured in n8n for Google Vertex AI, Google Sheets, Slack, and any API keys (like for NewsAPI.org).
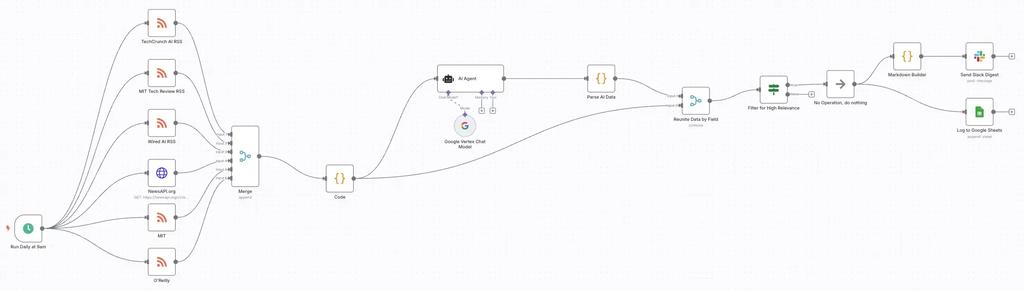
Configuring the Core Components: Data Sources and AI Analysis
Before we build the workflow itself, we need to configure n8n to connect to our news sources and Google's Vertex AI. This involves setting up credentials for external services and ensuring our AI model has the right parameters for analysis.
1. Setting up News Source Credentials
For most RSS feeds, no authentication is required. However, for NewsAPI.org, you'll need an API key:
- Get NewsAPI Key: Visit newsapi.org and sign up for a free account to get your API key.
- Add HTTP Header Auth Credential: In n8n's "Credentials" section, create a new "HTTP Header Auth" credential. Set the header name to
X-API-Keyand the value to your NewsAPI key.
2. Setting up Vertex AI (Gemini) Credentials
Just like in our previous project, we need to configure access to Google's Vertex AI:
- Enable Vertex AI API: In Google Cloud Console, ensure the Vertex AI API is enabled for your project.
- Create Service Account: Create a service account with
Vertex AI Userrole. - Generate JSON Key: Download the service account JSON key file.
- Add Credentials to n8n: In n8n's "Credentials" section, add a "Google Service Account" credential and paste the entire JSON content.
The n8n Workflow Canvas
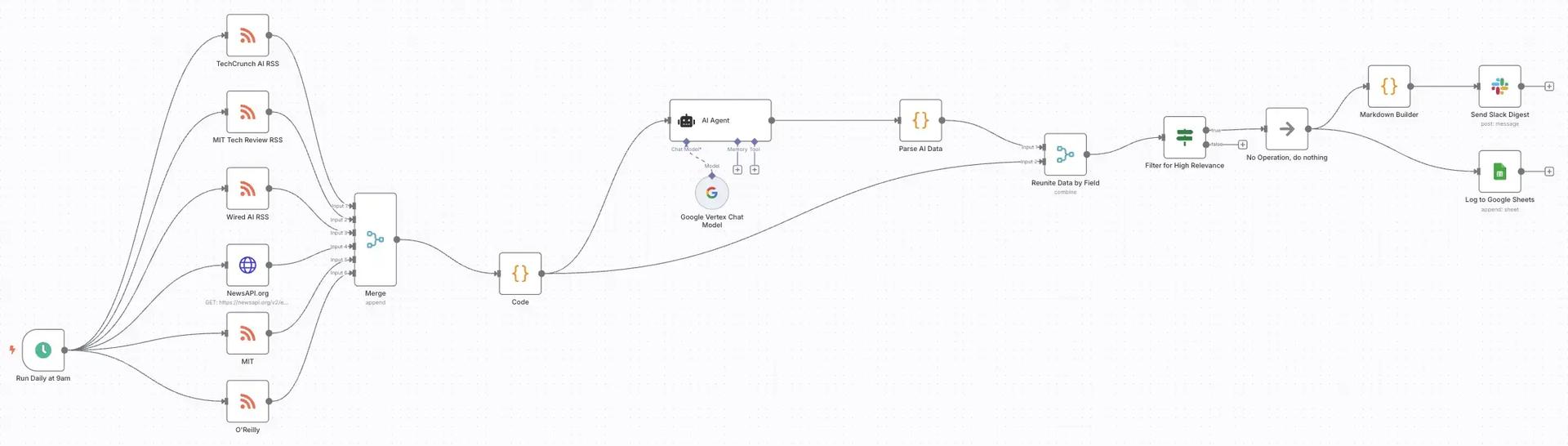
The final workflow is data processing pipeline that you can visually trace from the initial trigger, through multiple data sources, AI analysis, and finally to curated delivery.
Part 1: The Foundation - Daily Trigger and Data Aggregation
The workflow begins with a robust data collection system:
Schedule Trigger (
Run Daily at 9am): The workflow is initiated by aSchedule Triggernode configured to run once daily at 9:00 AM, ensuring the team gets a fresh digest at the start of their day.Data Ingestion (Multiple RSS/HTTP Nodes): The trigger simultaneously activates six data-gathering nodes:
TechCrunch AI RSS- Fetches from TechCrunch's AI category feedMIT Tech Review RSS- Pulls from MIT Technology Review's AI sectionWired AI RSS- Gathers from Wired's AI tag feedMIT- Additional MIT news source covering broader AI researchO'Reilly- O'Reilly Radar for technical AI/ML contentNewsAPI.org- Pulls recent AI articles from across the web using their API
Aggregation (
MergeNode): All these diverse news sources feed into a singleMergenode configured with 6 inputs. This node combines the disparate lists of articles into one large batch, ready for processing.
Part 2: The Brain - AI-Powered Analysis with Vertex AI
This is where the real intelligence comes in. The merged batch of articles is passed to our AI analysis engine.
Correlation ID Assignment (
CodeNode): Before AI processing, we pass the data through aCodenode that adds a uniquecorrelation_idto each article. This simple but crucial step ensures we can correctly match AI analysis results back to their original articles later.const items = $items(); items.forEach((item, index) => { item.json.correlation_id = index; }); return items;AI Agent (
AI AgentNode): We use n8n's powerfulAI Agentnode, connected to aGoogle Vertex Chat Modelnode configured to usegemini-2.0-flash-lite-001. The heart of this node is the carefully crafted prompt that instructs the LLM to act as an analysis agent and return findings in a specific JSON format.The System Prompt:
You are an AI analysis agent in an n8n workflow. Your task is to analyze technology articles and return the findings as a structured JSON object. **Analysis Instructions:** Based on the following article content, perform the analysis detailed below. **Article Title:** `{{$json.title}}` **Article Content:** `{{$json.contentSnippet || $json.content || 'No content available.'}}` **Required JSON Structure:** Generate a JSON object with the exact following fields and data types: 1. `summary` (string): A concise, one-paragraph summary of the article's main points. 2. `keywords` (array of strings): An array of 5 to 7 key topics or technologies mentioned. 3. `sentiment` (string): The overall sentiment of the article. Must be one of the following exact values: "Positive", "Negative", or "Neutral". 4. `is_ai_native_trend` (boolean): `true` if the trend is specific to 'AI Native' companies or technologies (built from the ground up with AI at their core), otherwise `false`. 5. `relevance_score` (integer): A numerical score from 1 (not relevant) to 10 (highly relevant) indicating how relevant this article is for identifying a significant new AI trend. 6. `correlation_id` (integer): The ID of the article. The ID for the article you are processing is: {{$json.correlation_id}} **CRITICAL OUTPUT RULE:** You MUST return ONLY the raw JSON object. Your response must not contain any explanatory text, comments, or markdown formatting such asjson.
By demanding a strict JSON output, we make the AI's response machine-readable and easy to parse in subsequent steps.Google Vertex Chat Model Configuration: The AI Agent is powered by a
Google Vertex Chat Modelnode configured with:- Project ID: Your Google Cloud project with Vertex AI enabled
- Model Name:
gemini-2.0-flash-lite-001for fast, cost-effective analysis - Credentials: The Google Service Account we configured earlier
Part 3: The "Janitor" - Data Wrangling with Code Nodes
The AI processing happens in a batch, but we need to correctly correlate the AI's analysis with the original article. This requires a clever data wrangling pattern that ensures data integrity throughout the pipeline.
Parsing (
Parse AI DataCode Node): After the AI Agent, the output is often a raw string that needs to be parsed. We use aCodenode to robustly parse this string, extract the JSON object, and handle any potential errors or formatting inconsistencies from the LLM.const allAIItems = $items(); const allParsedItems = []; for (const [index, item] of allAIItems.entries()) { const aiResponseString = item.json.output; if (typeof aiResponseString !== 'string' || aiResponseString.trim() === '') { continue; } const jsonMatch = aiResponseString.match(/{[\s\S]*}/); if (!jsonMatch) { continue; } const cleanedJsonString = jsonMatch[0]; try { const parsedJson = JSON.parse(cleanedJsonString); // Add the correct ID based on the item's position in the list. parsedJson.correlation_id = index; allParsedItems.push(parsedJson); } catch (error) { continue; } } return allParsedItems;Reuniting (
Reunite Data by FieldMerge Node): This is a critical step. We use aMergenode in "Combine" mode with two inputs:- The original list of articles (each with its
correlation_id) - The list of parsed AI analyses (each also containing a
correlation_id)
The merge node matches them by
correlation_id, effectively enriching the original article data with its new AI-generated summary, score, and keywords.- The original list of articles (each with its

Part 4: The Curator - Filtering and Delivering the Digest
Now that we have a complete, enriched dataset for each article, we can produce our final output.
Filtering (
Filter for High RelevanceIf Node): We use anIfnode to filter the stream, configured to only allow items to pass whererelevance_scoreis greater than7. This discards the noise and keeps only the signal—articles that our AI has determined are genuinely relevant to current AI trends.Parallel Processing: The filtered, high-relevance articles are then sent to two parallel paths for different types of output:
Archiving (
Log to Google Sheets): One path leads to aGoogle Sheetsnode, which appends the filtered articles as new rows to a spreadsheet. This creates a valuable, long-term archive of important trends with all the AI-generated metadata for future analysis and can be used as source for other content workflows.Formatting and Sending (
Markdown BuilderandSend Slack Digest): The other path leads to aCodenode that dynamically builds a beautiful, readable Markdown-formatted digest. This node processes all the filtered articles and creates a single, comprehensive message:const digestLines = items.map(item => { const d = item.json; return [ `### ${d.title}`, `**Relevance:** ${d.relevance_score}/10 | **Sentiment:** ${d.sentiment}`, `**Summary:** ${d.summary}`, `**Keywords:** \`${d.keywords.join(', ')}\``, `[Read More](${d.link})` ].join("\n"); }); const header = `## 📈 Top AI Trends Digest for ${new Date().toLocaleDateString('de-DE', { timeZone: 'Europe/Berlin' })}\n\n` + `Here are the most relevant AI trends identified today:\n\n`; return [{ json: { digest: header + digestLines.join("\n\n---\n\n"), } }];The output of this node is then passed to a
Send Slack Digestnode, which posts the formatted message to the designated Slack channel.
The Final Result: A Daily Slack Digest
The team receives a well formatted message in Slack that looks something like this:
📈 Top AI Trends Digest for 26.6.2025
Here are the most relevant AI trends identified today:
Meta’s recruiting blitz claims three OpenAI researchers
Relevance: 7/10 | Sentiment: Neutral Summary: Meta has reportedly hired three researchers from OpenAI, including those who established OpenAI's Zurich office, marking a win for Meta in its ongoing > recruitment efforts and highlighting the competition for top AI talent between Meta and OpenAI. Keywords: Meta, OpenAI, AI Talent, Recruiting, Superintelligence, Zuckerberg Read More ---
Federal judge sides with Meta in lawsuit over training AI models on copyrighted books
Relevance: 7/10 | Sentiment: Neutral Summary: A federal judge ruled in favor of Meta in a lawsuit filed by 13 authors, including Sarah Silverman, who claimed Meta illegally trained its AI models using > their copyrighted books. Keywords: Meta, AI Models, Copyright, Lawsuit, Authors, Artificial Intelligence Read More ---
This digest is automatically posted to your designated Slack channel every morning, while a complete record with all metadata is simultaneously archived in Google Sheets for historical analysis and trend tracking.
Advanced Configuration and Customization
The beauty of this n8n workflow is its flexibility. You can easily adapt it to your specific needs:
Customizing News Sources
Adding new news sources is straightforward—simply add additional RSS or HTTP nodes to the merge operation. Some valuable sources to consider:
- Academic Sources: arXiv RSS feeds for cutting-edge research
- Industry-Specific: Add feeds for your particular domain (fintech AI, healthcare AI, etc.)
- Company Blogs: Direct feeds from AI companies you're tracking
- Regional Sources: Local tech news for market-specific insights
Tuning the AI Analysis
The AI prompt can be customized for your specific interests:
- Relevance Criteria: Modify the scoring criteria to focus on your industry
- Additional Fields: Add fields for competitive analysis, technology readiness, or implementation complexity
- Sentiment Granularity: Expand beyond Positive/Negative/Neutral to include confidence scores
Delivery Customization
The output formatting can be tailored to your team's preferences:
- Multiple Channels: Send different relevance thresholds to different Slack channels
- Executive Summaries: Create condensed versions for leadership
- Email Digests: Replace or supplement Slack with email delivery
- Integration with Task Management: Automatically create follow-up tasks for high-priority trends
Quality Assurance
Regularly audit the AI's decisions:
- False Positives: Articles marked as highly relevant but actually not useful
- False Negatives: Important articles that might have been filtered out
- Analysis Quality: Spot-check summaries and keyword extraction for accuracy
Summary: Building the Foundation of Your Content Intelligence Engine
In this post, we've demonstrated how to move beyond simple automation and build a pipeline that serves as the foundation for a comprehensive content engine. By combining n8n's robust workflow engine with the analytical power of Google's Vertex AI, we've created a system that transforms the daily deluge of news into a strategic asset—but this is just the beginning.
Core Content Engine Capabilities We've Built
We've seen how to:
- Aggregate data from multiple disparate sources (RSS feeds and APIs) using n8n's flexible node system—creating the ingestion layer for any content engine
- Leverage an LLM with a precise, structured prompt to perform consistent, reliable analysis across hundreds of articles—establishing the analytical foundation that can be applied to any content type
- Apply sophisticated data wrangling techniques to maintain data integrity through complex AI processing pipelines—building the data architecture that scales beyond news to any content workflow
- Curate and filter information based on AI-generated relevance scores, ensuring only valuable insights reach your team—creating the intelligence layer that separates signal from noise
- Deliver actionable intelligence directly to your team's workspace in Slack, while maintaining a searchable archive for long-term analysis—establishing the distribution and retention systems every content engine needs
From News Curation to Content Intelligence Platform
This workflow represents much more than a news digest system—it's the architectural blueprint for a scalable content intelligence engine. The patterns we've established here can be extended to create a comprehensive content ecosystem:
Content Ingestion at Scale: The RSS and API integration patterns can easily accommodate social media feeds, internal documents, customer feedback, competitor analysis, research papers, and industry reports. Each new content type simply requires adding the appropriate source nodes to our merge operation.
Intelligent Content Classification: The AI analysis framework we've built can be adapted to categorize any content type. Whether you're analyzing sales calls for customer sentiment, research papers for technical feasibility, or social media for brand perception, the same structured prompt approach ensures consistent, actionable insights.
Dynamic Content Routing: The filtering and delivery mechanisms we've implemented can power sophisticated content distribution strategies. High-priority insights can trigger immediate alerts, while lower-priority content feeds into knowledge bases or weekly summaries. The system becomes a content traffic controller, ensuring the right information reaches the right people at the right time.
Historical Intelligence Building: The Google Sheets archival system we've implemented creates the foundation for long-term trend analysis, competitive intelligence, and strategic planning. Over time, this becomes an organizational memory that can inform decision-making and identify patterns invisible in day-to-day operations.
Unlike our previous Kubernetes-based deployment, this solution demonstrates the power of n8n's built-in capabilities to handle complex data processing entirely within the platform itself. The result is a more streamlined architecture that's easier to deploy, maintain, and modify—perfect for rapid iteration as your content engine requirements evolve.
The Strategic Advantage: From Information Overload to Competitive Intelligence
This pattern isn't limited to AI news. The same architectural principles can be adapted to track competitor activity, monitor market sentiment, analyze customer feedback from various channels, or any other use case that requires transforming high-volume, unstructured information into focused, actionable intelligence. It's a powerful blueprint for building systems that help your team work smarter, not just harder, in an age where information abundance often becomes information paralysis.
The key insight is that effective AI-powered curation isn't just about filtering—it's about creating intelligence systems that understand context, maintain consistency, and deliver insights precisely when and where your team needs them most. When you build this foundation correctly, you're not just solving today's information overload problem; you're creating the infrastructure for tomorrow's AI-powered decision-making processes.
Your content engine starts here. But where it goes depends on how creatively you apply these patterns to the unique information challenges your organization faces. The workflow we've built today is the kernel of a system that can grow into your organization's central nervous system for processing, understanding, and acting on the flood of information that shapes modern business.
MCP is one piece of a larger shift in how engineering organisations build and operate with AI. Our book, From Cloud Native to AI Native, covers the full picture — from architecture through to operating model — and what we've learned in practice. Download it for free!.
Table of Contents
Let's Talk About a Problem We All Know - Taming the AI News Firehose
The Engine Room: n8n for Intelligent Data Processing
Architectural Overview: From Raw Feeds to Intelligent Digest
Crafting the AI Curation Workflow in n8n
Advanced Configuration and Customization
Summary: Building the Foundation of Your Content Intelligence Engine


Continue Exploring
You Might Also Like

A Pattern Language for Transformation
Browse our interactive library of 119 transformation patterns. Each one describes a specific architectural problem and a tested way to solve it, so your team can talk about real tradeoffs instead of abstract ideas.