
Waves of InnovationPatterns
The shared language of AI Native Transformation
Strategy requires a shared vocabulary. We have mapped 119 recurring patterns of innovation, from Cloud Native to AI Native, to help you anticipate friction, design resilient systems, and align your team around a common roadmap.
Pattern Language
A Pattern Language for the AI Native Wave
This is the complete, interactive library of the transformation and paradigm patterns from our book, "Waves of Innovation." It's a practical, hands-on tool designed to give you and your team a shared vocabulary for navigating the complexities of the AI Native wave.



Why Patterns matter
Why a Pattern Language?
To navigate complex shifts, you need a shared vocabulary. A 'pattern language', an idea from architect Christopher Alexander, is a collection of proven, reusable solutions to common challenges.
As he argued, we can only consciously choose what we can name and discuss. These patterns are that language, helping you make better design choices and lead richer, more collaborative discussions with your team.
How to Use The Patterns
Three Ways to Put the Patterns into Practice

The Workshop Toolkit
A Self-Facilitated Workshop Guide
Run a powerful, self-facilitated strategy session with your team. This free toolkit provides the instructions and posters you need to diagnose your current state and build an actionable roadmap using our pattern language. if you need any help.
Prefer expert guidance? We can organize and facilitate a tailored workshop at your company, handling everything from preparation to actionable outcomes.
Click to see Work shop poster


The "How-To"
The Instructions Guide
This guide walks you through exactly how to run the session, from managing the time to guiding the conversation. If anything is unclear, feel free to reach out to us. We'd be happy to help.
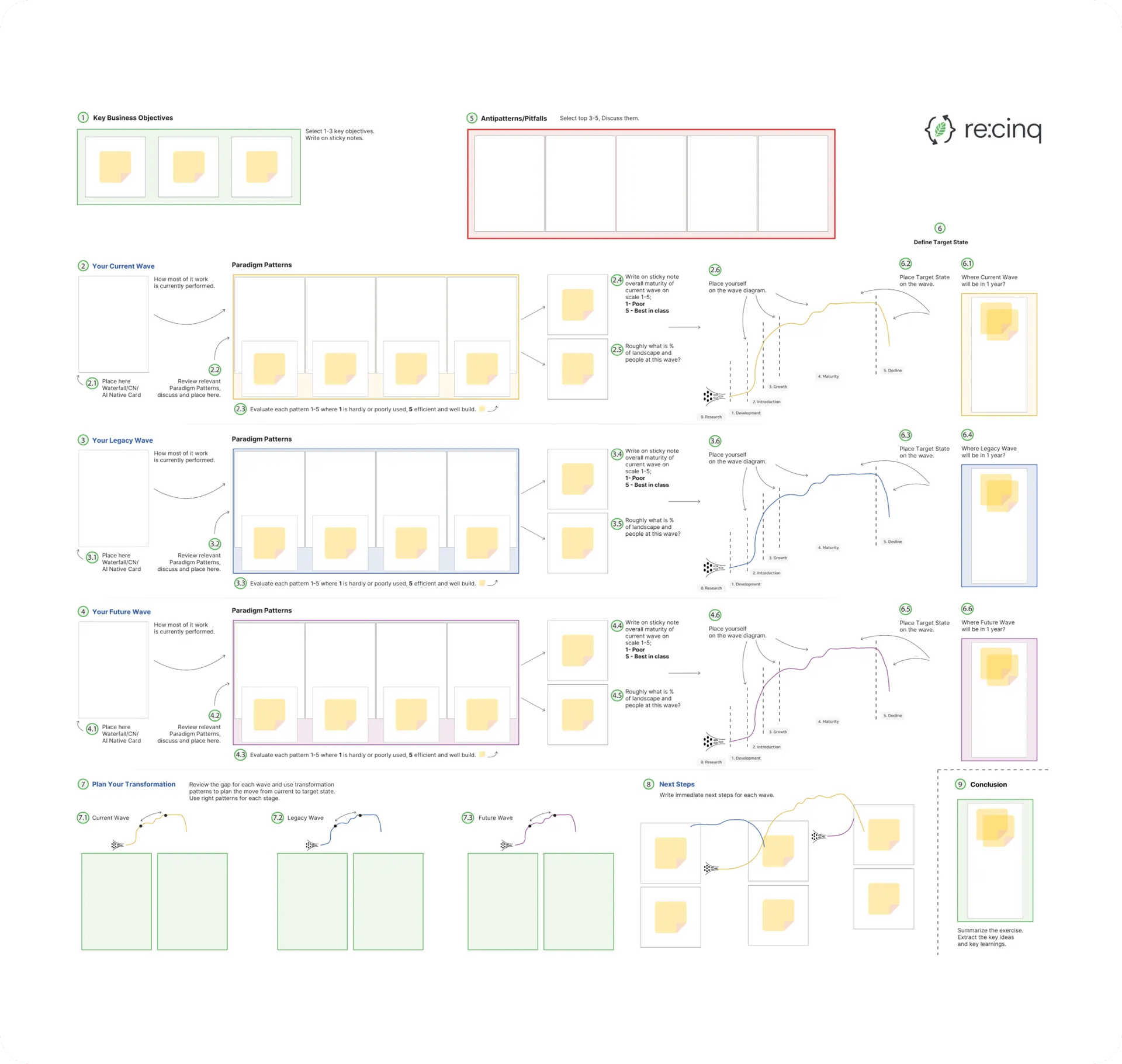
Original poster size: 1130x980mm. Contact us for a full-sized print copy.




From Cloud Native to AI Native: Catching the Next Wave of Innovation
As Described In The Book
The complete theory, real-world case studies, and detailed descriptions of every pattern are found in our new book. Reading it is the best way to get the deep context needed to facilitate a powerful strategic conversation with your team. This entire ecosystem of tools begins with the book.
Case Studies included by :