



What are Large Language Models and Key Terminologies

Large Language Models (LLMs) have changed the field of natural language processing (NLP), powering applications from chatbots and virtual assistants to machine translation and content generation. Models like OpenAI's GPT-4, Anthropic's Claude 3.5 Sonnet or Google' Gemini 1.5 have demonstrated remarkable results in generating human-like text, performing complex reasoning, and even passing professional exams. But what exactly are LLMs, and what are the key concepts that underpin their functionality?
In this blog post, we'll explore what Large Language Models are and explain essential terminologies associated with them.
What Are Large Language Models?
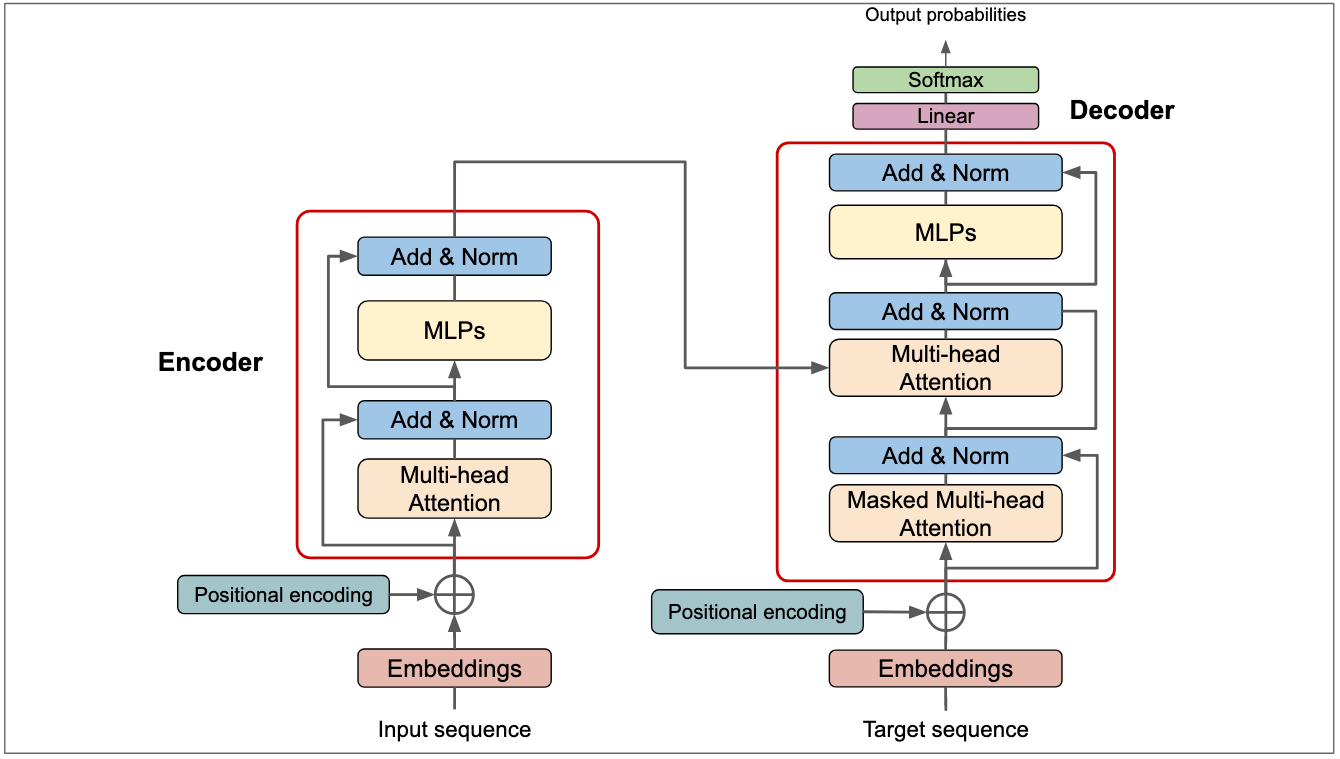
Large Language Models are advanced neural networks trained on huge amounts of textual data to understand, generate, and manipulate human language. They are characterized by their large number of parameters—often billions or even trillions—which enable them to capture complex patterns, syntax, and semantics in language.
LLMs are designed to predict the next word in a sentence, a simple objective that leads to capabilities in language understanding and generation. Through extensive training, these models learn the probability distribution of word sequences, allowing them to generate coherent and contextually relevant text.
Key Characteristics of LLMs:
- Extensive Training Data: Trained on diverse datasets that include books, articles, websites, and more.
- Large Number of Parameters: High parameter count allows modeling complex language patterns.
- Versatility: Capable of performing various NLP tasks without task-specific training.
The Core Objective: Predicting the Next Word
At the heart of LLMs lies a fundamental task: predicting the next word in a sequence given the preceding words. This seemingly simple task enables the model to learn the statistical properties of language, capturing both short-term and long-term dependencies.
Emergent Abilities:
As LLMs scale in size and data, they show capabilities in unexpected areas where these models haven't been trained for. Examples include:
- Arithmetic Calculations: Solving mathematical problems.
- Language Translation: Translating text between languages.
- Question Answering: Providing answers to factual and reasoning-based questions.
- Passing Professional Exams: Demonstrating proficiency in specialized domains like medicine and law.
These abilities emerge because the models learn complex patterns and relationships in the data, enabling them to generalize knowledge across different tasks.
Key Terminologies in LLMs
Understanding the following key concepts is essential to grasp how LLMs function.
Language Modeling
Language modeling involves learning the probability distribution over sequences of words. By predicting the likelihood of a word given the preceding words, LLMs can generate coherent text.
Example:
- Predicting the word "York" after "I live in New" because it's statistically more probable than unrelated words like "shoe."
Tokenization
Tokenization is the process of breaking down text into smaller units called tokens. Tokens can be sentencesm words, subwords, or characters. Effective tokenization is crucial for model performance.
Consider the following sentence:
"She exclaimed, "I'll never forget the well-known author's life's work!"
1. Whitespace Tokenization:
["She", "exclaimed,", ""I'll", "never", "forget", "the", "well-known", "author's", "life's", "work!"]
- Explanation: Splits text at whitespace. Punctuation and contractions remain attached to words, which may not be ideal for analysis.
2. Punctuation-Based Tokenization:
["She", "exclaimed", ",", "\"", "I", "'ll", "never", "forget", "the", "well", "-", "known", "author", "'s", "life", "'s", "work", "!", "\""]
- Explanation: Separates punctuation and handles contractions by splitting them into constituent parts, which can help the model understand the grammatical structure.
3. Subword Tokenization (Byte-Pair Encoding):
["She", "ex", "claim", "ed", ",", "\"", "I", "'ll", "never", "for", "get", "the", "well", "-", "known", "author", "'s", "life", "'s", "work", "!", "\""]
Explanation: Breaks down words into smaller subword units. This is beneficial for handling rare or complex words by decomposing them into familiar components.
Benefits of Subword Tokenization:
- Handles Rare Words: By splitting words into subwords, the model can interpret and generate rare or unseen words.
- Reduces Vocabulary Size: Fewer unique tokens are needed, as words are constructed from subword units.
- Improves Morphological Understanding: Helps the model grasp prefixes, suffixes, and root words, enhancing its understanding of language structure.

Embeddings
Embeddings convert tokens into numerical vectors that capture semantic meaning. Similar words have embeddings that are close in the vector space.
- Purpose: Allows the model to understand relationships between words.
- Creation: Initialized randomly and adjusted during training to minimize prediction errors.
Training and Fine-Tuning
- Pre-training: The model learns language structures by predicting next tokens on large datasets like Common Crawl.
- Fine-Tuning: The pre-trained model is further trained on task-specific data to specialize in tasks like translation or summarization.
Prediction and Generation
LLMs generate text in an autoregressive manner, predicting one token at a time based on previous tokens. They output a probability distribution over possible next tokens, selecting one according to certain strategies (e.g., greedy search, beam search, sampling).
Context Size
Context size refers to the maximum number of tokens the model can process in a single input. Larger context sizes allow the model to consider more preceding text, leading to more coherent and contextually appropriate outputs.
- Examples:
- GPT-3: Up to 2,048 tokens.
- GPT-4: Up to 32,768 tokens.
Scaling Laws
Scaling laws describe how changes in model size, data size, and computational resources affect performance. Research (e.g., the Chinchilla paper) has shown that there are optimal balances between these factors.
Key Points:
- Number of Parameters (N): Determines the model's capacity to learn from data.
- Training Dataset Size (D): The amount of data (in tokens) the model is trained on.
- Compute Budget (FLOPs): The computational resources used during training.
Optimal Training: The Chinchilla authors trained hundreds of models and reported an optimal token-to-parameter ratio (TPR) of roughly 20. For a model with ( N ) parameters, it should be trained on approximately ( N * 20 ) tokens.
Emergent Abilities in LLMs
Emergent abilities are skills that appear in LLMs as they scale, without explicit development of this capabilities.
- Zero-Shot Learning: Performing tasks without prior examples.
- Commonsense Reasoning: Making inferences like a human would.
- Unscrambling Words: Rearranging letters to form meaningful words.
These abilities highlight the potential of LLMs to generalize knowledge and perform complex tasks.
Conclusion
Large Language Models represent a significant advancement in AI and NLP, with capabilities in understanding and generating human language. By leveraging architectures like transformers and concepts like tokenization and embeddings, LLMs can perform a wide array of tasks, often without task-specific training.
Understanding the key terminologies and concepts behind LLMs is essential for anyone interested in AI, as these models continue to influence technology. As research progresses, we can expect LLMs to become even more capable, opening up new possibilities and challenges in the field of artificial intelligence.
Table of Contents
What Are Large Language Models?
The Core Objective: Predicting the Next Word
Key Terminologies in LLMs
Conclusion



Continue Exploring
You Might Also Like

A Pattern Language for Transformation
Browse our interactive library of 119 transformation patterns. Each one describes a specific architectural problem and a tested way to solve it, so your team can talk about real tradeoffs instead of abstract ideas.